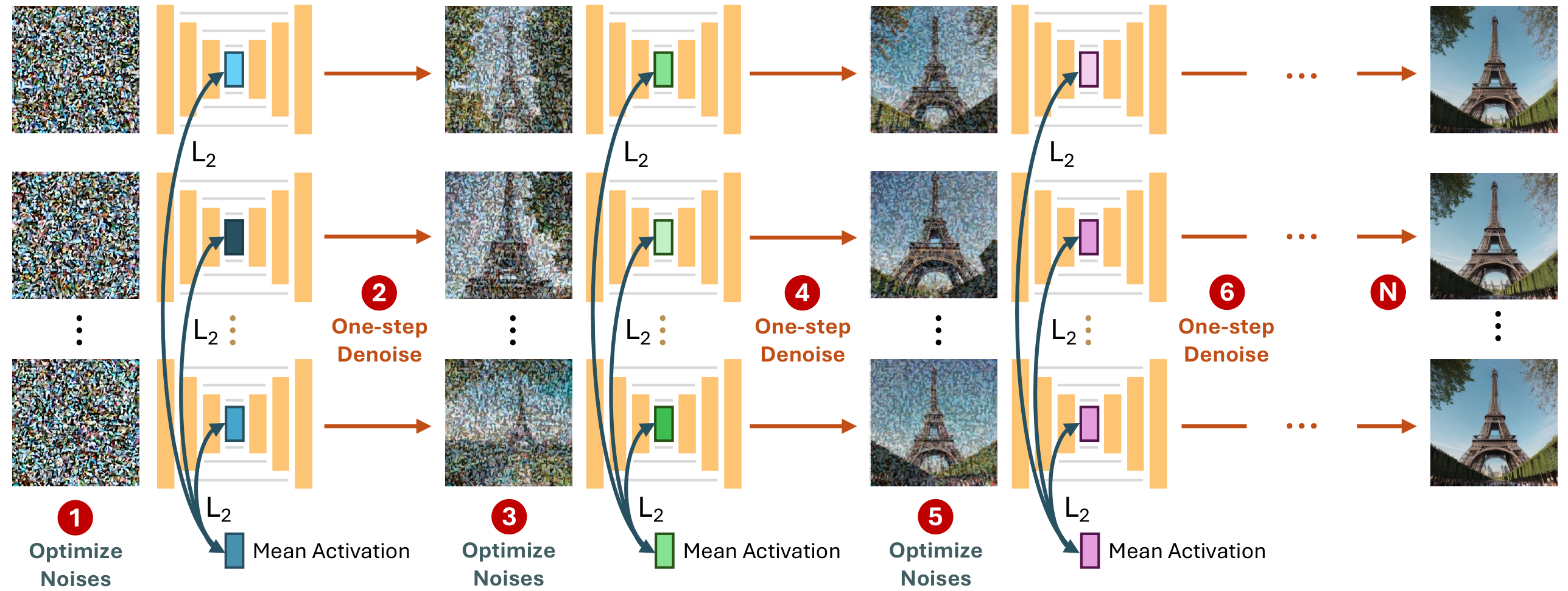
Code (Coming Soon)
Code (Coming Soon)

"Strength"

"Denver"

"Wizard"

"Marriage"

"Breakfast"

"Clock"

"Aurora"

"Alien"

"Fear"

"Jellyfish"

"CEO"

"Childhood"

"Santorini"

"Cat"

"Dance"

"Intelligence"

"Ferris Wheel"

"Peace"

"Giraffe"

"Kungfu Master"
"Strength"
"Denver"
"Wizard"
"Marriage"
"Breakfast"
"Clock"
"Aurora"
"Alien"
"Fear"
"Jellyfish"
"CEO"
"Childhood"
"Santorini"
"Cat"
"Dance"
"Intelligence"
"Ferris Wheel"
"Peace"
"Giraffe"
"Kungfu Master"